Beyond Stateless Conversations: Adding Long-Term Memory to Your Foundry Agents
If you’ve worked with AI agents in production, you’ve almost certainly run into this problem: a user tells your agent something important in one session, and the next time they come back, the agent has completely forgotten about it. The user has to repeat themselves. Context is lost. The experience feels disjointed.
I ran into this exact issue while working on a project where users were interacting with an enterprise agent multiple times throughout the day. They’d establish context in the morning — their role, the documents they cared about, the format they preferred for summaries — and then come back after lunch to find the agent had no memory of any of it. We ended up building a workaround that involved stuffing conversation history into prompts and maintaining our own embedding store. It worked, but it added latency, cost, and a fair amount of code that had nothing to do with the actual business logic.
When Microsoft announced the public preview of Memory in Foundry Agent Service at Ignite 2025, I was genuinely interested. Not because the concept of agent memory is new — we’ve all built our own versions of it — but because the promise was that all of that plumbing would be handled by the platform itself. No custom embedding databases, no retrieval pipelines, no manual consolidation logic.
If you’ve been following my previous posts on building Bing Search agents, SharePoint grounding, and delegated permissions, you know I like to dig into these features hands-on and see what actually works in practice. In this post, I’ll walk through what Foundry Agent Memory is, how it works under the hood, and how to implement it in .NET — since the official documentation currently only covers Python and REST.
The Problem with Stateless Agents
Most agents built on top of large language models are stateless by design. Each conversation starts fresh. The model receives a prompt, generates a response, and moves on. There’s no built-in mechanism to carry information from one session to the next.
Developers have tried various approaches to work around this:
- Conversation History Injection: Loading previous conversation turns into the system prompt or message history. This works for short-term context but quickly eats into your token budget as conversations grow. It’s also not selective — you’re injecting everything, not just what’s relevant.
- Custom Vector Stores: Extracting key information from conversations, embedding it, and storing it in something like Azure AI Search or a dedicated vector database. This gives you semantic retrieval, but you’re now responsible for the entire pipeline — extraction logic, embedding management, index maintenance, conflict resolution when facts change.
- Database-Backed State: Storing structured user preferences in a traditional database and injecting them into prompts. Simple and effective for known attributes, but it doesn’t scale well to unstructured or evolving information.
Each of these approaches works to varying degrees, but they all share a common problem: you’re spending a significant amount of development effort on infrastructure that isn’t your core product. You’re building and maintaining a memory system instead of focusing on the agent behaviour that actually matters to your users.
What Foundry Agent Memory Actually Does
Memory in Foundry Agent Service is a managed, long-term memory store that’s natively integrated with the agent runtime. Instead of you building and maintaining the extraction and retrieval pipeline, the service handles it automatically.
The process works in four phases:
- Extract: As the user interacts with the agent, the system identifies and pulls out key information — preferences, facts, context that’s likely to be relevant in future sessions. For instance, if a user mentions they work in the finance department and prefer bullet-point summaries, the system captures that.
- Consolidate: Extracted memories are merged and deduplicated. If the user previously said they prefer dark roast coffee and later mentions they’ve switched to light roast, the system uses an LLM to resolve the conflict and update the memory rather than storing both.
- Retrieve: At the start of each new conversation, the system uses hybrid search to surface relevant memories. Core profile facts (like dietary restrictions or role) are injected immediately. Contextual memories are retrieved per turn based on the latest messages.
- Customize: The user_profile_details parameter lets you tell the system what kinds of information matter for your specific use case. A travel agent might prioritize airline preferences and dietary restrictions. A developer support agent might focus on programming languages and framework versions.
Memory Types
The system supports two types of memory:
- User Profile: Static facts about the user that remain relevant across sessions — preferences, roles, restrictions. These are retrieved at the beginning of every conversation regardless of what the user asks.
- Chat Summary: Condensed summaries of previous conversations. These provide contextual continuity — the agent can reference what was discussed last time without needing to replay the entire conversation history.
Scoping and Isolation
Memory is partitioned using the scope parameter. Each scope maintains an isolated collection of memory items. In most scenarios, you’d scope memory to individual users — using their Entra ID, a UUID, or {{$userId}} which automatically extracts the tenant and object ID from the authentication header.
This is important for enterprise scenarios where you absolutely cannot have one user’s memory leaking into another user’s conversations. Each scope is a completely separate partition.
Prerequisites and Setup
Before we start coding, make sure you have the following in place:
Azure Requirements
- Azure Subscription with access to Microsoft Foundry
- Microsoft Foundry Project — if you haven’t set one up yet, refer to Step 1 in my earlier post on Bing Search Agents
- Azure AI User RBAC Role assigned to your identity
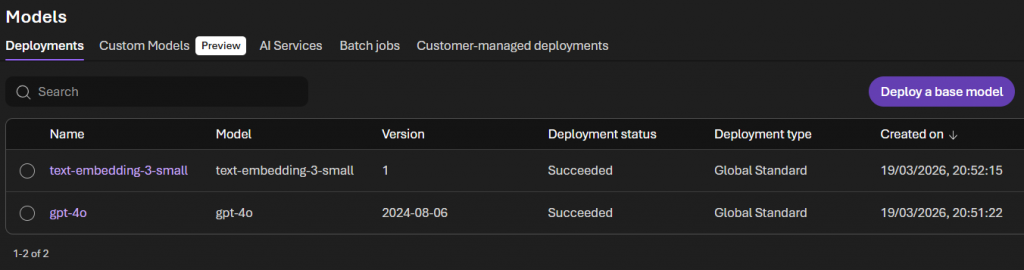
Model Deployments
You’ll need two model deployments in your Foundry project:
- Chat Model: Such as
gpt-4oorgpt-5.2— this handles the memory extraction and consolidation logic - Embedding Model: Such as
text-embedding-3-small— this powers the semantic search when retrieving memories
Navigate to your Foundry project’s “Models + Endpoints” section and deploy both if you haven’t already. Note down the deployment names.
Development Environment
You will need:
- .NET 8.0 or later
- Visual Studio 2022 (or later) or VS Code
Important Note on the SDK
As of March 2026, the Foundry Agent Service memory feature is in public preview. The .NET SDK (Azure.AI.Projects version 2.0.0-beta.1) is still catching up with full memory support. The Python SDK has first-class support through project_client.beta.memory_stores, and the REST API is fully documented.
For this post, I’ll be wrapping the REST API in a clean .NET service class. This is actually the approach I’d recommend for any preview feature — it gives you full control, it’s easy to debug, and when the SDK adds native support, you can swap out the implementation without changing your application code.
Step 1: Project Setup
Create a new .NET console application or add to your existing agent project. Here are the packages you’ll need:
<PackageReference Include="Azure.Identity" Version="1.13.2" />
<PackageReference Include="Microsoft.Extensions.Configuration" Version="10.0.5" />
<PackageReference Include="Microsoft.Extensions.Configuration.Json" Version="10.0.5" />
<PackageReference Include="Microsoft.Extensions.DependencyInjection" Version="10.0.5" />
<PackageReference Include="Microsoft.Extensions.Hosting" Version="10.0.5" />
<PackageReference Include="Microsoft.Extensions.Http" Version="10.0.5" />
<PackageReference Include="Microsoft.Extensions.Logging" Version="10.0.5" />
<PackageReference Include="Microsoft.Extensions.Logging.Console" Version="10.0.5" />Configuration
Update your appsettings.json:
{
"Foundry": {
"ProjectEndpoint": "https://{your-ai-services-account}.services.ai.azure.com/api/projects/{project-name}",
"ApiVersion": "2025-11-15-preview",
"AgentApiVersion": "2025-11-15-preview",
"TenantId": "TENANT_ID"
},
"Models": {
"ChatModel": "gpt-4o",
"EmbeddingModel": "text-embedding-3-small"
},
"Memory": {
"StoreName": "enterprise_memory_store",
"StoreDescription": "Long-term memory for enterprise assistant",
"UserProfileDetails": "Capture the user's role, department, document preferences, and frequently accessed topics. Avoid sensitive data such as financial details, credentials, and personal identifiers.",
"UpdateDelaySeconds": 60
}
}A few notes on the configuration:
UserProfileDetails is where you tell the memory system what to focus on. Be specific. If you leave this vague, the system will try to capture everything, which leads to noisy memories and higher costs.
UpdateDelaySeconds controls the debounce period before memories are written. After each agent response, the system schedules a memory update, but only commits it after this period of inactivity. For testing, you can set this to 0 or 1. In production, something like 300 (5 minutes) is reasonable — it prevents excessive writes during rapid back-and-forth exchanges.
Step 2: Memory Store Service
The MemoryStoreService class handles all interactions with the Foundry Memory Store API. Since we’re working with the REST API directly, this gives us full visibility into what’s happening.
using System.Net.Http.Headers;
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
using Azure.Identity;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Logging;
namespace FoundryMemoryStoreDemo;
public class MemoryStoreService
{
private readonly HttpClient _httpClient;
private readonly IConfiguration _configuration;
private readonly ILogger<MemoryStoreService> _logger;
private readonly DefaultAzureCredential _credential;
private readonly string _endpoint;
private readonly string _apiVersion;
public MemoryStoreService(
HttpClient httpClient,
IConfiguration configuration,
ILogger<MemoryStoreService> logger)
{
_httpClient = httpClient;
_configuration = configuration;
_logger = logger;
_endpoint = _configuration["Foundry:ProjectEndpoint"]
?? throw new InvalidOperationException("Foundry project endpoint is not configured");
_apiVersion = _configuration["Foundry:ApiVersion"] ?? "2025-11-15-preview";
var tenantId = _configuration["Foundry:TenantId"];
_credential = string.IsNullOrEmpty(tenantId)
? new DefaultAzureCredential()
: new DefaultAzureCredential(new DefaultAzureCredentialOptions { TenantId = tenantId });
}
private async Task SetAuthHeaderAsync()
{
var token = await _credential.GetTokenAsync(
new Azure.Core.TokenRequestContext(["https://ai.azure.com/.default"]));
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token.Token);
}
public async Task<bool> CreateMemoryStoreAsync(string storeName)
{
await SetAuthHeaderAsync();
var chatModel = _configuration["Models:ChatModel"] ?? "gpt-4o";
var embeddingModel = _configuration["Models:EmbeddingModel"] ?? "text-embedding-3-small";
var description = _configuration["Memory:StoreDescription"] ?? "Agent memory store";
var profileDetails = _configuration["Memory:UserProfileDetails"] ?? "";
var payload = new
{
name = storeName,
description,
definition = new
{
kind = "default",
chat_model = chatModel,
embedding_model = embeddingModel,
options = new
{
chat_summary_enabled = true,
user_profile_enabled = true,
user_profile_details = profileDetails
}
}
};
var content = new StringContent(
JsonSerializer.Serialize(payload, _jsonOptions),
Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync(
$"{_endpoint}/memory_stores?api-version={_apiVersion}", content);
if (response.IsSuccessStatusCode)
{
_logger.LogInformation("Memory store '{StoreName}' created successfully", storeName);
return true;
}
// Store might already exist — check for conflict
if (response.StatusCode == System.Net.HttpStatusCode.Conflict)
{
_logger.LogInformation("Memory store '{StoreName}' already exists", storeName);
return true;
}
var error = await response.Content.ReadAsStringAsync();
// API returns 400 BadRequest when store already exists (instead of 409)
if (response.StatusCode == System.Net.HttpStatusCode.BadRequest
&& error.Contains("already exists", StringComparison.OrdinalIgnoreCase))
{
_logger.LogInformation("Memory store '{StoreName}' already exists", storeName);
return true;
}
_logger.LogError("Failed to create memory store: {StatusCode} - {Error}",
response.StatusCode, error);
return false;
}
public async Task<string?> UpdateMemoriesAsync(
string storeName, string scope, string userMessage, string? previousUpdateId = null)
{
await SetAuthHeaderAsync();
var payload = new
{
scope,
items = new[]
{
new
{
type = "message",
role = "user",
content = new[]
{
new { type = "input_text", text = userMessage }
}
}
},
update_delay = int.Parse(_configuration["Memory:UpdateDelaySeconds"] ?? "60"),
previous_update_id = previousUpdateId
};
var content = new StringContent(
JsonSerializer.Serialize(payload, _jsonOptions),
Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync(
$"{_endpoint}/memory_stores/{storeName}:update_memories?api-version={_apiVersion}",
content);
if (!response.IsSuccessStatusCode)
{
var error = await response.Content.ReadAsStringAsync();
_logger.LogError("Failed to update memories: {Error}", error);
return null;
}
var result = await response.Content.ReadAsStringAsync();
var doc = JsonDocument.Parse(result);
if (doc.RootElement.TryGetProperty("update_id", out var updateId))
{
_logger.LogInformation("Memory update queued with ID: {UpdateId}", updateId.GetString());
return updateId.GetString();
}
return null;
}
public async Task<List<MemoryItem>> SearchMemoriesAsync(
string storeName, string scope, string? query = null, int maxMemories = 10)
{
await SetAuthHeaderAsync();
object payload;
if (string.IsNullOrEmpty(query))
{
// Static retrieval — gets user profile memories without a query
payload = new
{
scope,
options = new { max_memories = maxMemories }
};
}
else
{
// Contextual retrieval — searches based on the query
payload = new
{
scope,
items = new[]
{
new
{
type = "message",
role = "user",
content = new[]
{
new { type = "input_text", text = query }
}
}
},
options = new { max_memories = maxMemories }
};
}
var content = new StringContent(
JsonSerializer.Serialize(payload, _jsonOptions),
Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync(
$"{_endpoint}/memory_stores/{storeName}:search_memories?api-version={_apiVersion}",
content);
if (!response.IsSuccessStatusCode)
{
var error = await response.Content.ReadAsStringAsync();
_logger.LogError("Failed to search memories: {Error}", error);
return [];
}
var result = await response.Content.ReadAsStringAsync();
var doc = JsonDocument.Parse(result);
var memories = new List<MemoryItem>();
if (doc.RootElement.TryGetProperty("memories", out var memoriesArray))
{
foreach (var memory in memoriesArray.EnumerateArray())
{
if (memory.TryGetProperty("memory_item", out var item))
{
memories.Add(new MemoryItem
{
MemoryId = item.GetProperty("memory_id").GetString() ?? "",
Content = item.GetProperty("content").GetString() ?? "",
MemoryType = item.TryGetProperty("type", out var type)
? type.GetString() ?? "unknown" : "unknown"
});
}
}
}
_logger.LogInformation("Retrieved {Count} memories for scope '{Scope}'",
memories.Count, scope);
return memories;
}
public async Task<bool> DeleteScopeAsync(string storeName, string scope)
{
await SetAuthHeaderAsync();
var payload = new { scope };
var content = new StringContent(
JsonSerializer.Serialize(payload, _jsonOptions),
Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync(
$"{_endpoint}/memory_stores/{storeName}:delete_scope?api-version={_apiVersion}",
content);
if (response.IsSuccessStatusCode)
{
_logger.LogInformation("Deleted memories for scope '{Scope}'", scope);
return true;
}
var error = await response.Content.ReadAsStringAsync();
_logger.LogError("Failed to delete scope: {Error}", error);
return false;
}
private static readonly JsonSerializerOptions _jsonOptions = new()
{
PropertyNamingPolicy = JsonNamingPolicy.SnakeCaseLower,
DefaultIgnoreCondition = JsonIgnoreCondition.WhenWritingNull
};
}
public class MemoryItem
{
public string MemoryId { get; set; } = "";
public string Content { get; set; } = "";
public string MemoryType { get; set; } = "";
}A few things worth noting about this implementation:
SetAuthHeaderAsync: Uses DefaultAzureCredential to get a token for the Foundry API. This handles both local development (where it picks up your Visual Studio or Azure CLI credentials) and production (where it uses managed identity).
CreateMemoryStoreAsync: Creates the memory store if it doesn’t already exist. I’ve added a check for 409 Conflict because in practice you’ll be calling this at application startup, and you don’t want it to fail if the store was already created in a previous run.
SearchMemoriesAsync: Supports two modes — static retrieval (no query, returns user profile memories) and contextual retrieval (with a query, returns relevant memories based on semantic similarity). The official documentation recommends using static retrieval at the start of each conversation and contextual retrieval for each subsequent turn.
UpdateMemoriesAsync: Sends conversation content to the memory store for extraction. The previous_update_id parameter allows you to chain updates across multiple conversation turns, which keeps the consolidation context intact.
Step 3: Agent with Memory
Now let’s build the agent class that brings memory into the conversation flow. This agent retrieves stored memories before responding and updates the memory store after each interaction.
using Azure.Identity;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Logging;
using System;
using System.Collections.Generic;
using System.Net.Http.Headers;
using System.Text;
using System.Text.Json;
namespace FoundryMemoryStoreDemo;
public class MemoryAgent
{
private readonly MemoryStoreService _memoryService;
private readonly IConfiguration _configuration;
private readonly ILogger<MemoryAgent> _logger;
private readonly HttpClient _httpClient;
private readonly DefaultAzureCredential _credential;
private readonly string _endpoint;
private readonly string _storeName;
private readonly string _agentApiVersion;
private string? _agentName;
private string? _conversationId;
private string? _lastUpdateId;
private string _scope = "dev_user_001";
public MemoryAgent(
MemoryStoreService memoryService,
HttpClient httpClient,
IConfiguration configuration,
ILogger<MemoryAgent> logger)
{
_memoryService = memoryService;
_httpClient = httpClient;
_configuration = configuration;
_logger = logger;
_endpoint = _configuration["Foundry:ProjectEndpoint"]
?? throw new InvalidOperationException("Foundry project endpoint not configured");
_storeName = _configuration["Memory:StoreName"] ?? "enterprise_memory_store";
_agentApiVersion = _configuration["Foundry:AgentApiVersion"] ?? "2025-11-15-preview";
var tenantId = _configuration["Foundry:TenantId"];
_credential = string.IsNullOrEmpty(tenantId)
? new DefaultAzureCredential()
: new DefaultAzureCredential(new DefaultAzureCredentialOptions { TenantId = tenantId });
}
private async Task<string> SetAuthHeaderAsync()
{
var tokenResult = await _credential.GetTokenAsync(
new Azure.Core.TokenRequestContext(["https://ai.azure.com/.default"]));
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", tokenResult.Token);
return tokenResult.Token;
}
private static string ResolveScopeFromToken(string jwt)
{
// JWT is three base64url parts separated by '.'
// Decode the payload (second part) to extract tid and oid claims
var parts = jwt.Split('.');
if (parts.Length < 2)
return "dev_user_001";
var payload = parts[1];
// Base64url → base64
payload = payload.Replace('-', '+').Replace('_', '/');
payload = payload.PadRight(payload.Length + (4 - payload.Length % 4) % 4, '=');
var json = System.Text.Encoding.UTF8.GetString(Convert.FromBase64String(payload));
var doc = JsonDocument.Parse(json);
var tid = doc.RootElement.TryGetProperty("tid", out var tidProp) ? tidProp.GetString() : null;
var oid = doc.RootElement.TryGetProperty("oid", out var oidProp) ? oidProp.GetString() : null;
if (!string.IsNullOrEmpty(tid) && !string.IsNullOrEmpty(oid))
return $"{tid}_{oid}";
return "dev_user_001";
}
public async Task InitializeAsync()
{
// Resolve the real user scope from the auth token (tid_oid format)
var token = await SetAuthHeaderAsync();
_scope = ResolveScopeFromToken(token);
_logger.LogInformation("Using memory scope: {Scope}", _scope);
// Create the memory store if it doesn't exist
var created = await _memoryService.CreateMemoryStoreAsync(_storeName);
if (!created)
throw new InvalidOperationException("Failed to create or verify memory store");
await SetAuthHeaderAsync();
var chatModel = _configuration["Models:ChatModel"] ?? "gpt-4o";
var updateDelay = int.Parse(_configuration["Memory:UpdateDelaySeconds"] ?? "5");
// Use a per-user agent name so the scope embedded in the tool definition is correct
// Name must be alphanumeric + hyphens only, start/end with alphanumeric, max 63 chars
var scopeHash = Math.Abs(_scope.GetHashCode()).ToString();
var agentName = $"MemoryAgent-{scopeHash[..Math.Min(8, scopeHash.Length)]}";
var agentPayload = new
{
name = agentName,
definition = new
{
kind = "prompt",
model = chatModel,
instructions = """
You are a helpful enterprise assistant. You have access to a memory system
that stores information about your users across conversations.
When a user shares information about themselves — their role, preferences,
projects they're working on, or anything else relevant — acknowledge it naturally.
You don't need to announce that you're "saving" it.
When you recall information from previous sessions, use it naturally in your
responses. Don't say "According to my memory" or "I recall from our previous
conversation." Just use the context as a knowledgeable assistant would.
If you're unsure whether stored context is still accurate, it's fine to
confirm with the user.
""",
tools = new[]
{
new
{
type = "memory_search",
memory_store_name = _storeName,
scope = _scope,
update_delay = updateDelay
}
}
}
};
var content = new StringContent(
JsonSerializer.Serialize(agentPayload),
Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync(
$"{_endpoint}/agents?api-version={_agentApiVersion}", content);
if (response.IsSuccessStatusCode)
{
var result = await response.Content.ReadAsStringAsync();
var doc = JsonDocument.Parse(result);
_agentName = doc.RootElement.GetProperty("name").GetString();
_logger.LogInformation("Agent '{AgentName}' initialized with memory", _agentName);
return;
}
// Agent already exists — reuse it
if (response.StatusCode == System.Net.HttpStatusCode.Conflict)
{
_agentName = agentName;
_logger.LogInformation("Agent '{AgentName}' already exists, reusing it", _agentName);
return;
}
var error = await response.Content.ReadAsStringAsync();
throw new InvalidOperationException($"Failed to create agent: {error}");
}
public async Task StartNewConversationAsync()
{
await SetAuthHeaderAsync();
var response = await _httpClient.PostAsync(
$"{_endpoint}/openai/v1/conversations",
new StringContent("{}", Encoding.UTF8, "application/json"));
if (!response.IsSuccessStatusCode)
{
var error = await response.Content.ReadAsStringAsync();
throw new InvalidOperationException($"Failed to create conversation: {response.StatusCode} - {error}");
}
var result = await response.Content.ReadAsStringAsync();
var doc = JsonDocument.Parse(result);
_conversationId = doc.RootElement.GetProperty("id").GetString();
_logger.LogInformation("Started conversation: {ConversationId}", _conversationId);
// Retrieve static memories to show what the agent knows about this user
var staticMemories = await _memoryService.SearchMemoriesAsync(_storeName, _scope);
if (staticMemories.Count > 0)
{
_logger.LogInformation("Loaded {Count} stored memories for this user", staticMemories.Count);
}
}
public async Task<string> SendMessageAsync(string userMessage)
{
if (_conversationId == null || _agentName == null)
throw new InvalidOperationException("Call InitializeAsync and StartNewConversationAsync first");
await SetAuthHeaderAsync();
// The memory_search tool on the agent handles retrieval and update automatically per turn
var payload = new
{
input = userMessage,
conversation = _conversationId,
agent_reference = new
{
type = "agent_reference",
name = _agentName
}
};
var content = new StringContent(
JsonSerializer.Serialize(payload),
Encoding.UTF8, "application/json");
var response = await _httpClient.PostAsync(
$"{_endpoint}/openai/v1/responses", content);
if (!response.IsSuccessStatusCode)
{
var error = await response.Content.ReadAsStringAsync();
_logger.LogError("Agent response failed: {Error}", error);
return "I'm sorry, I encountered an error processing your request.";
}
var result = await response.Content.ReadAsStringAsync();
var doc = JsonDocument.Parse(result);
// Extract the text response from the output array
var outputText = "";
if (doc.RootElement.TryGetProperty("output", out var output))
{
foreach (var item in output.EnumerateArray())
{
if (item.TryGetProperty("type", out var type) &&
type.GetString() == "message")
{
if (item.TryGetProperty("content", out var msgContent))
{
foreach (var part in msgContent.EnumerateArray())
{
if (part.TryGetProperty("text", out var text))
outputText += text.GetString();
}
}
}
}
}
// Fall back to output_text if available
if (string.IsNullOrEmpty(outputText) &&
doc.RootElement.TryGetProperty("output_text", out var fallbackText))
{
outputText = fallbackText.GetString() ?? "";
}
return outputText;
}
public async Task ShowStoredMemoriesAsync()
{
var memories = await _memoryService.SearchMemoriesAsync(_storeName, _scope);
if (memories.Count == 0)
{
Console.WriteLine(" (No memories stored yet for this user)");
return;
}
foreach (var memory in memories)
{
Console.WriteLine($" [{memory.MemoryType}] {memory.Content}");
}
}
public async Task ClearMemoriesAsync()
{
await _memoryService.DeleteScopeAsync(_storeName, _scope);
}
}A few design decisions worth explaining:
Agent Instructions: I spent some time tuning the system prompt. The key is telling the agent to use memory naturally. If you don’t include guidance here, the agent tends to announce that it’s recalling information from memory, which feels unnatural. Users don’t want to hear “According to my stored records, you prefer…” — they want the agent to just know.
Conversation Management: Each call to StartNewConversationAsync creates a fresh conversation with the Foundry Responses API. The memory system operates independently of the conversation — memories are stored per scope, not per conversation. So when a user starts a new conversation, the agent still has access to everything it learned from previous ones.
Scope: I’m using a static scope for development. In production, you’d pull this from the authenticated user’s identity — either their Entra object ID or {{$userId}} if you’re using the agent tool approach.
Step 4: Main Application
using FoundryMemoryStoreDemo;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
var builder = Host.CreateApplicationBuilder(args);
var configuration = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddEnvironmentVariables()
.Build();
builder.Services.AddSingleton<IConfiguration>(configuration);
builder.Services.AddHttpClient<MemoryStoreService>();
builder.Services.AddHttpClient<MemoryAgent>();
builder.Services.AddSingleton<MemoryStoreService>();
builder.Services.AddSingleton<MemoryAgent>();
builder.Services.AddLogging(logging =>
{
logging.AddConsole();
logging.SetMinimumLevel(LogLevel.Information);
});
var host = builder.Build();
var logger = host.Services.GetRequiredService<ILogger<Program>>();
var agent = host.Services.GetRequiredService<MemoryAgent>();
try
{
logger.LogInformation("Initializing Memory Agent...");
await agent.InitializeAsync();
Console.WriteLine("\n=== Foundry Agent with Long-Term Memory ===");
Console.WriteLine("Commands:");
Console.WriteLine(" /memories - Show stored memories for this user");
Console.WriteLine(" /clear - Clear all memories for this user");
Console.WriteLine(" /new - Start a new conversation (memories persist)");
Console.WriteLine(" /exit - Exit the application\n");
await agent.StartNewConversationAsync();
while (true)
{
Console.Write("\nYou: ");
var input = Console.ReadLine();
if (string.IsNullOrEmpty(input))
continue;
switch (input.ToLower().Trim())
{
case "/exit":
goto exit;
case "/memories":
Console.WriteLine("\nStored memories:");
await agent.ShowStoredMemoriesAsync();
continue;
case "/clear":
await agent.ClearMemoriesAsync();
Console.WriteLine("Memories cleared.");
continue;
case "/new":
await agent.StartNewConversationAsync();
Console.WriteLine("New conversation started. Memories from previous sessions are still available.");
continue;
}
var response = await agent.SendMessageAsync(input);
Console.WriteLine($"\nAssistant: {response}");
}
}
catch (Exception ex)
{
logger.LogError(ex, "An error occurred: {Message}", ex.Message);
}
exit:
logger.LogInformation("Application completed");
await host.StopAsync();The /memories command is useful during development — it lets you inspect what the agent has actually stored, so you can verify that your user_profile_details configuration is capturing the right information.
The /new command demonstrates the core value of memory. Start a conversation, establish some context (“I’m a .NET developer working on SharePoint integrations”), then type /new to start a fresh conversation. When you ask the agent a question in the new session, it should already know your background.
Testing the Memory Flow
Here’s a realistic test scenario to verify everything is working:
Session 1 — Establish context:
You: Hi, I'm a senior developer at Contoso. I work primarily with SharePoint Online and Azure AI services. I prefer code examples in C#.
Assistant: Welcome! What are you working on?
You: Building a SharePoint Agent for searching HR policy documentsNow type /memories to see what was captured:
Stored memories:
[user_profile] Senior developer at Contoso, works with SharePoint Online and Azure AI services
[user_profile] Prefers code examples in C#
[chat_summary] User is building an agent for searching HR policy documents in SharePointSession 2 — Start a new conversation and test recall:
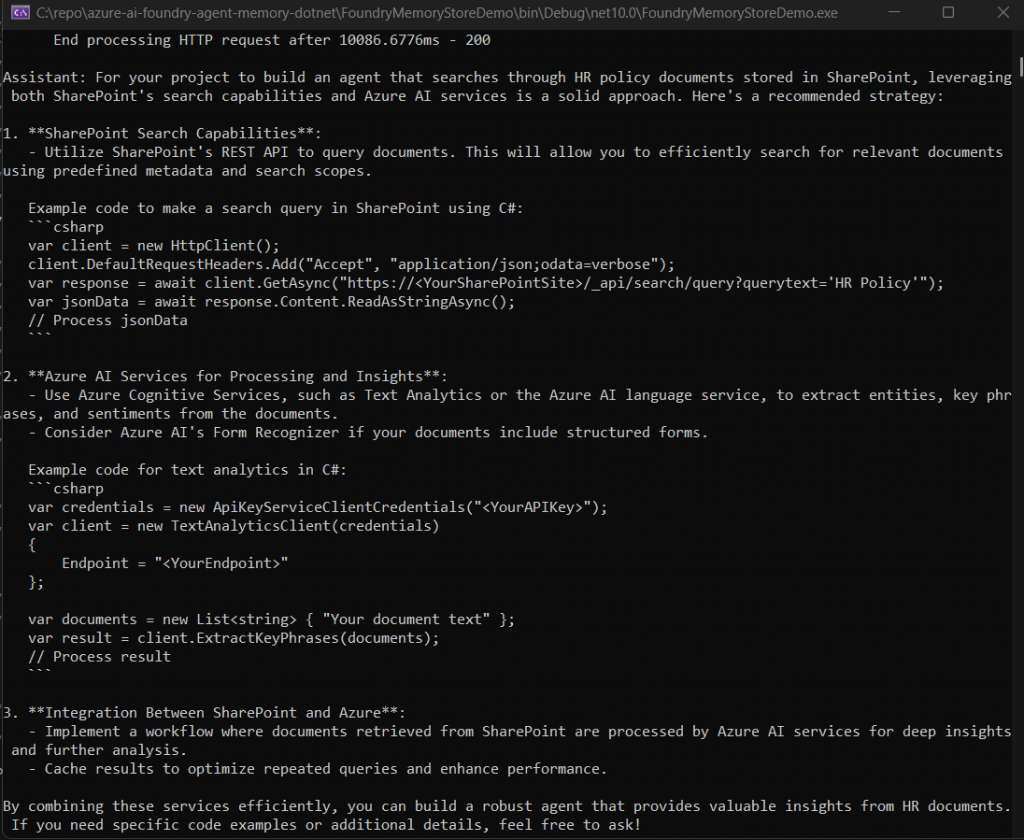
Type /new to start a fresh conversation, then:
You: What approach would you recommend for my current project?
Assistant: For your project to build an agent that searches through HR policy documents stored in SharePoint, leveraging both SharePoint's search capabilities and Azure AI services is a solid approach. Here's a recommended strategyThe agent knew the user works at Contoso, prefers C#, and is building a SharePoint HR document agent — all from the previous session. The user didn’t repeat any of that context. That’s the value of long-term memory.
Limitations and Things to Watch Out For
This feature is in public preview, and there are some practical constraints you should be aware of before building anything production-facing on top of it:
- Storage Limits: Each scope can hold up to 10,000 memory items. For most use cases this is plenty, but if you’re building an agent that serves thousands of users, keep an eye on per-user memory growth. You can use the user_profile_details parameter to be selective about what gets stored.
- Throughput: The system is capped at 1,000 requests per minute during preview. This includes both read and write operations. For a development or pilot scenario this is fine, but if you’re planning a large-scale rollout, factor this into your capacity planning.
- Write Latency: Memory updates are debounced by the update_delay setting. If you set this to 60 seconds (the default when using the agent tool), memories won’t appear immediately after a conversation turn. During testing, set it to 0 or 1 so you can verify extraction is working. In production, a higher value like 300 seconds prevents excessive writes during rapid exchanges.
- SDK Support: As of March 2026, the Python SDK has first-class support for memory through project_client.beta.memory_stores. The .NET SDK (Azure.AI.Projects 2.0.0-beta.1) doesn’t yet have equivalent helper classes, which is why I used the REST API directly in this post. When the .NET SDK GA drops — which Microsoft has indicated is imminent — I expect memory support to be included. I’ll update the GitHub repo when that happens.
- Consolidation Behaviour: The LLM-based consolidation that merges and deduplicates memories is not fully deterministic. In my testing, it generally did a good job of resolving conflicts (user says they like dark roast, later says they switched to light roast), but occasionally it would store both versions. This behaviour may change as the preview evolves.
- No Granular Deletion: You can delete all memories for a scope or delete the entire memory store, but you can’t currently delete individual memory items through the API. If a user asks you to forget a specific piece of information, your only option is to clear their entire scope and let the memories rebuild from subsequent conversations.
Cost Considerations
During the public preview, the memory feature itself is free — you’re not charged for memory storage or the memory management operations. However, you are billed for the underlying model usage:
Chat Model Costs: The extraction and consolidation phases use your deployed chat model (e.g., GPT-4o) to process conversation content and merge memories. Each conversation turn that triggers a memory update incurs token usage against your chat model deployment.
Embedding Model Costs: The retrieval phase uses your embedding model (e.g., text-embedding-3-small) to perform semantic search across stored memories. Each search operation — both static retrieval at conversation start and contextual retrieval per turn — incurs embedding token costs.
In practice, the costs are modest for development and pilot scenarios. For a rough estimate: if each memory update processes about 500 tokens through GPT-4o and each search generates about 200 embedding tokens, a user who has 10 conversations per day would cost roughly a few cents per day in model usage. The real cost driver at scale is the chat model used for extraction and consolidation, not the embedding model.
Keep in mind that pricing may change when the feature moves to general availability. Monitor your usage through the Foundry portal and set up budget alerts if you’re running a larger pilot.
Conclusion
We’ve covered a lot of ground in this post:
- The Problem: Why stateless agents create a poor user experience and the common workarounds developers use
- The Solution: How Foundry Agent Memory works — extraction, consolidation, retrieval, and customisation
- The Implementation: A complete .NET implementation using the REST API, including memory store management, agent creation with the memory search tool, and a conversation loop that demonstrates cross-session recall
- Practical Guidance: Testing strategies, current limitations, and cost considerations
The code in this post is intentionally structured to be extensible. The MemoryStoreService can be reused across different agent types, and the REST API wrapper can be swapped out for the native .NET SDK once it ships with memory support.
In Part 2, I’ll take this further by combining memory with the SharePoint grounding tool — building an enterprise assistant that not only searches your SharePoint content intelligently, but also remembers what each user has asked about before, their role, and their preferences. That combination of personalised context and enterprise knowledge is where these agents start to feel genuinely useful rather than just technically impressive.
Source Code
Access the complete source code for this blog post on GitHub: GitHub Repository Link